How to Import Data from S3
The / Forensic Acquisition and Investigation platform supports acquiring data from AWS S3 buckets. The two primary use cases for S3 data acquisition are:
- Analyzing disk images or zip files uploaded to an S3 bucket as part of an investigation.
- Analyzing the contents of an S3 bucket for any uploaded files that may be part of an incident.
Steps to Import from S3
-
On your investigation select import > Cloud > AWS >
-
Select your account then select S3
-
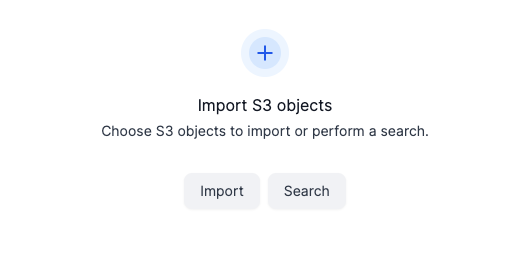
Select to Import or Search Choose the bucket you need, navigate through the objects, and select the files you want to import.
- Import will allow you to import the full S3 bucket that you select.
- Search will allow you to use parameters to grep into specific folders inside your S3 bucket
-
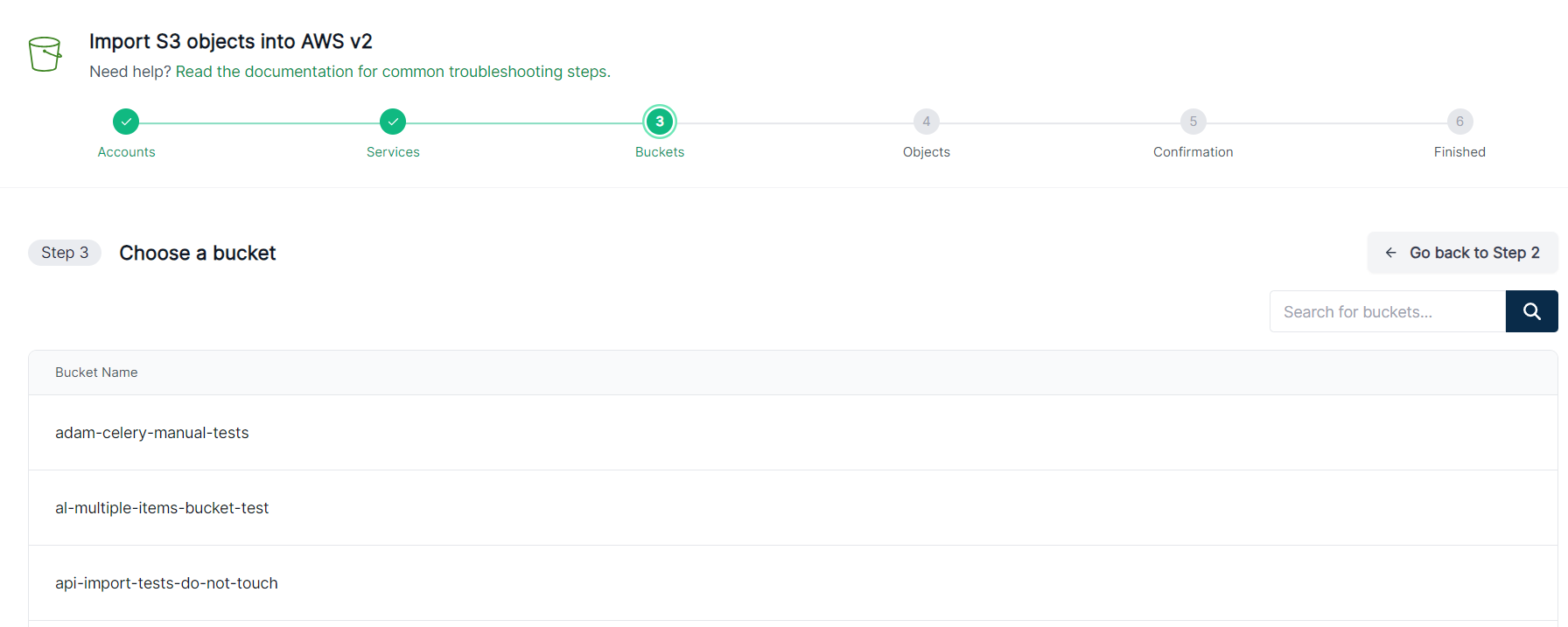
Select the bucket you would like to import or search.
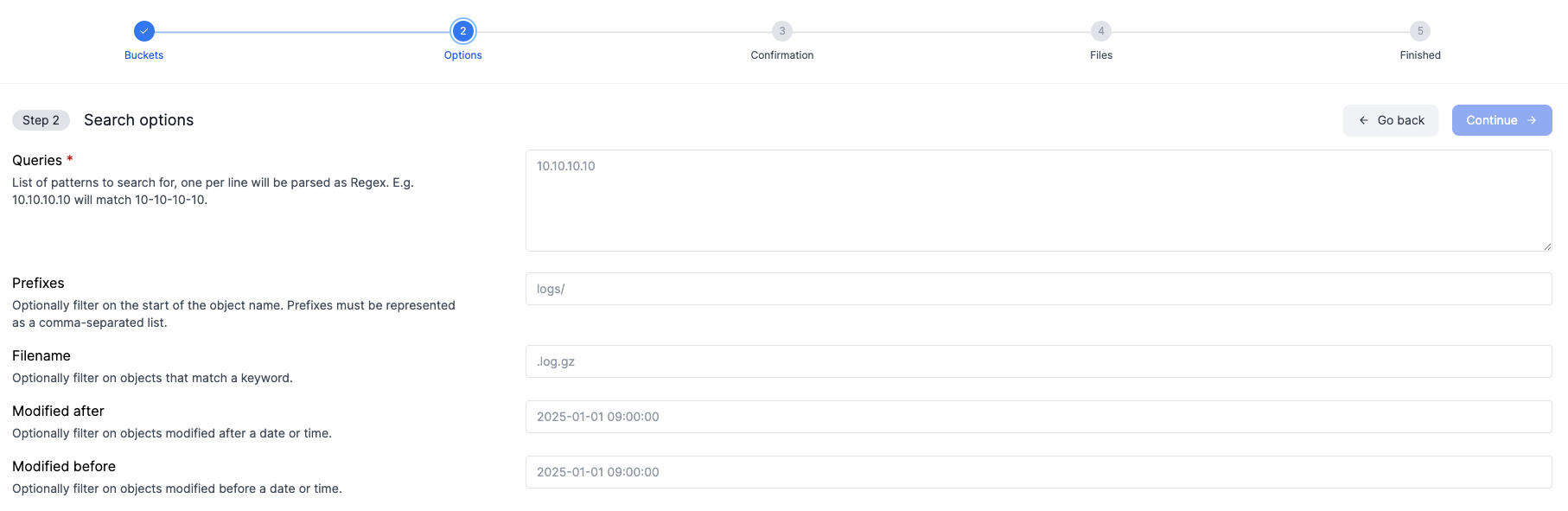
- If you selected search you will have to fill our search fields as seen in the screenshot below.
-
Click the 'Import objects' button.
-
Confirm the Details and click Start Import to begin the acquisition process.
Uploading On-Premise Evidence to S3 for Import
If you have access to the AWS Console, you can upload data directly from your web browser. Alternatively, you can create an AWS Access and Secret Key and use a desktop GUI tool like Cyberduck to upload files, with features like resuming failed uploads.
Recommendations for Using Access Keys
If you create access keys for uploading data to S3, we recommend the following:
- Scope the access by giving the associated role write-only access to a single S3 bucket. For more details, see Write-Only Access.
- Use temporary credentials when possible. Learn more about this in Cyberduck’s S3 documentation.
Using / Forensic Acquisition and Investigation Host for Upload
If you don’t have direct access to AWS, you can use / Forensic Acquisition and Investigation Host with the --single_file_unzipped parameter. / Forensic Acquisition and Investigation will generate the necessary credentials when you go to Import > Cado Host.
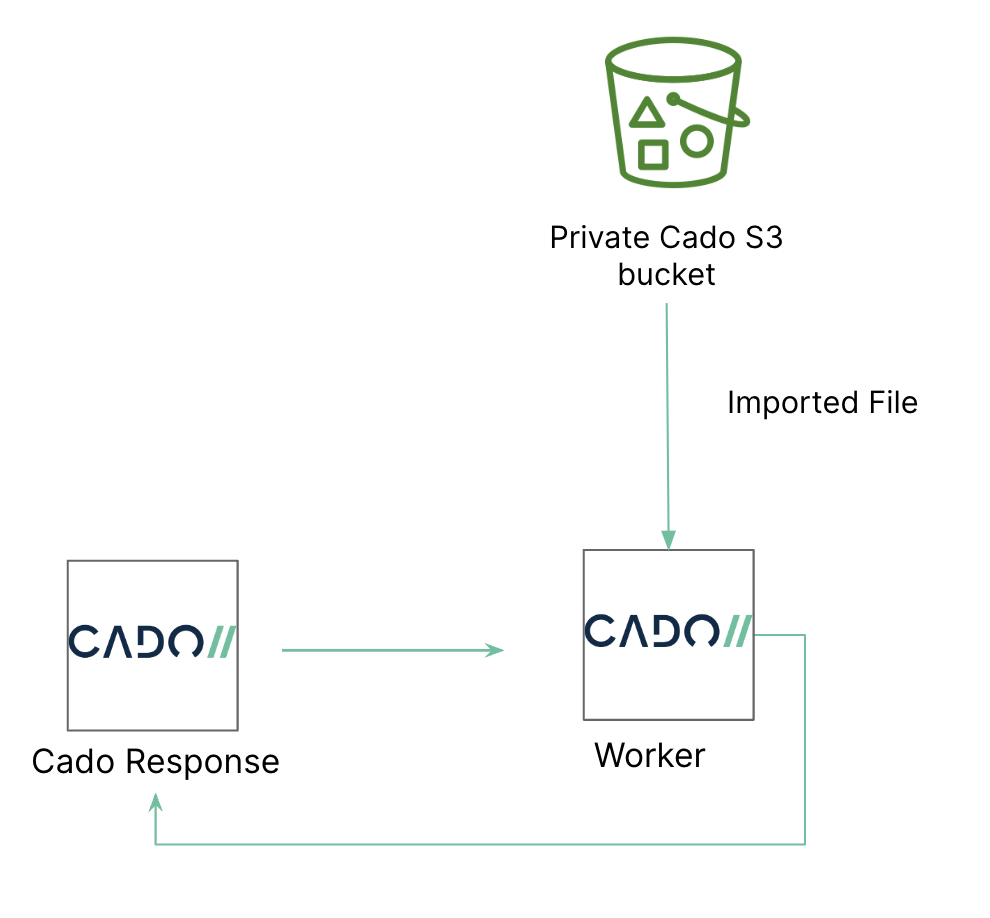
Data Flow Diagram
The following diagram shows how S3 acquisitions work: